OCR AND VLM FOR DOCUMENT EXTRACTION IN 2026

The Death of Pure OCR Has Been Greatly Exaggerated — But the Era of Intelligent Visual Understanding Has Arrived
Scope of OCR in 2025–2026
OCR remains a foundational, high-volume technology focused on extracting text from images/PDFs/scans. It is mature, fast, cost-effective, and widely deployed at scale.
Key Current & Growing Applications
- Document management & digitization (largest segment ~42%)
- Invoice/receipt scanning, accounts payable automation
- Data entry automation, form processing
- Identity verification (KYC, passports, IDs)
- Banking/Financial services (compliance, transactions, cheque)
- Healthcare (patient records, prescriptions)
- Retail/e-commerce (receipts, product labels)
- Government/public sector (archives, forms)
- Procurement & supply chain (contracts, supplier docs)
- Real-time mobile OCR (translation, AR apps)

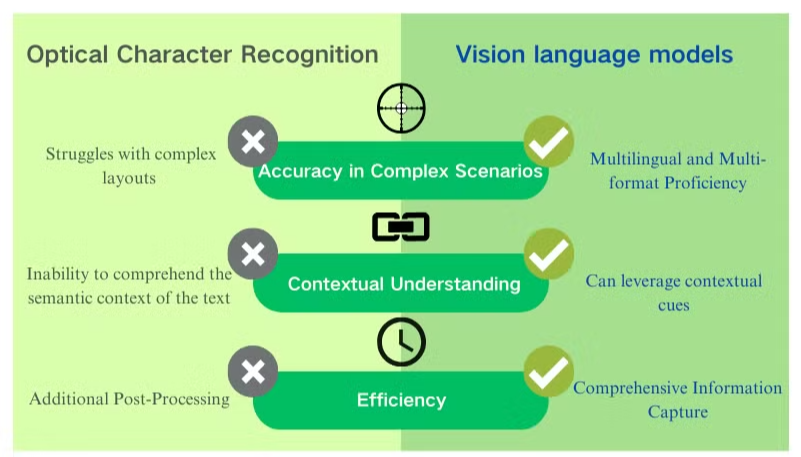
In 2026, document AI has evolved far beyond simple text scanning. Traditional OCR still powers high-volume, cost-effective extraction for clean printed documents, but messy real-world files—handwritten notes, skewed scans, borderless tables, charts, diagrams, mixed scripts, and noisy archives—demand more. Multimodal Vision Language Models (VLMs) and agentic platforms now deliver holistic understanding: layout preservation, contextual reasoning, structured outputs (Markdown, JSON, HTML), and multilingual prowess.
This blog explores the current landscape, key models like Chandra OCR, Tesseract, Sarvam Vision, and enterprise solutions like LandingAI's Agentic Document Extraction (ADE), with visuals to illustrate benchmarks, architectures, and real extraction examples.
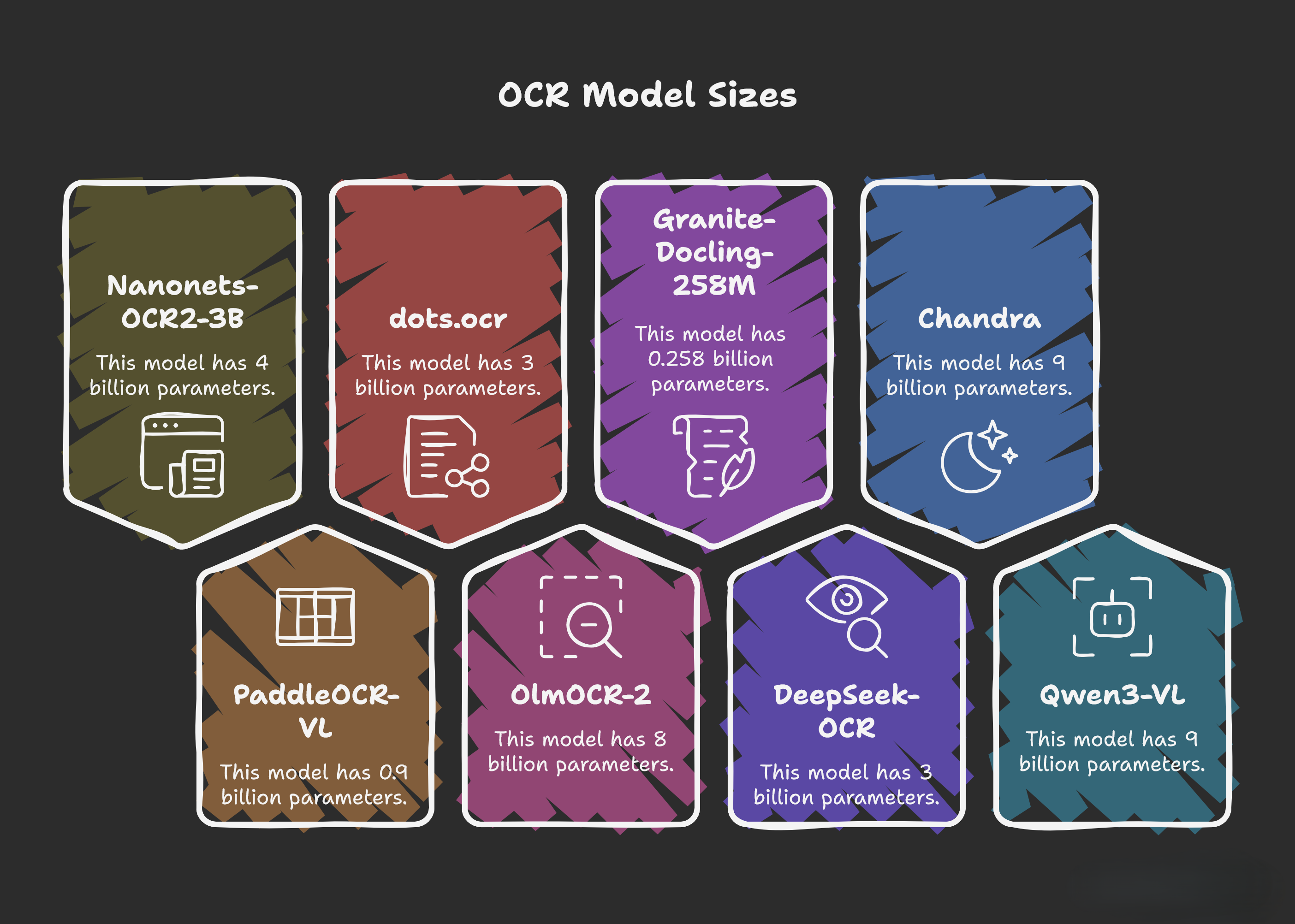
Latest Trends and Model Sizes
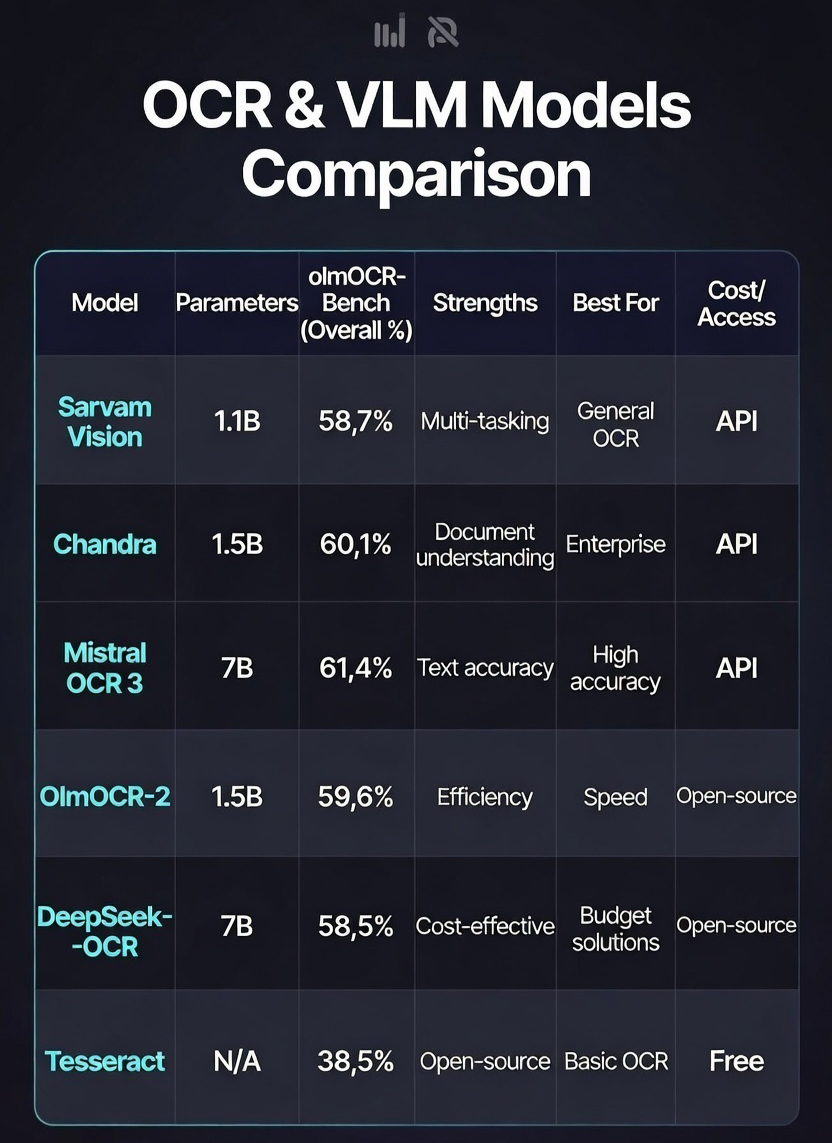
Multimodal OCR trends toward larger grounded models (Chandra 9B, OlmOCR-2 8B >83% average benchmarks) for reasoning-heavy tasks, plus efficient mid-sized ones (DeepSeek-OCR 3B, dots.ocr 3B) for tables, handwriting, charts, and structured outputs.
Smaller specialists excel: PaddleOCR-VL (0.9B) with 100+ languages and HTML conversion for legacy scans. Sarvam Vision (3B), launched early 2026, targets India with English + 22 official languages (Hindi, Tamil, Telugu, Bengali, Marathi, Kannada, Gujarati, Punjabi, Malayalam, Urdu, Assamese). It scores 84.3% on olmOCR-Bench (English subset), beating Gemini 3 Pro and DeepSeek variants on Indic scripts, multi-column layouts, noisy historical texts, textbooks, forms, and archives—vital for government, education, and banking KYC in diverse linguistic regions.
The big picture: Scalability + multilingual depth + structured reasoning = true document intelligence.
Key Points on Chandra OCR (9B Multimodal Model)
Released by Datalab in late 2025 (OpenRAIL-M license), Chandra is an open-source powerhouse for complex document-to-structured output (Markdown, HTML, JSON) with full layout fidelity—including headers/footers, tables, forms (checkboxes), math equations, diagrams, and captioned images.
- Leads olmOCR-Bench at 83.1% overall (top open-source), excelling in tables (88.0%), old scans/math (80.3%), handwriting, and layout tasks—often surpassing proprietary models like GPT-4o.
- Strong multilingual (40+ languages incl. Chinese, Japanese, Korean, English) with excellent handwriting and form reconstruction.
- Handles messy real-world docs: doctor notes, historical manuscripts, charts, embedded figures; full-page processing avoids chunking errors.
- Fast & affordable: ~14.5 pages/sec inference, ~$0.002/page via vLLM/Hugging Face.
Perfect when high-fidelity structure trumps post-processing.
Key Points on Tesseract OCR (Classic Open-Source Engine)
Tesseract (v5.x in 2026, Google/community-maintained) is free, offline, CPU-efficient, and supports 100+ languages. Outputs plain text, hOCR (HTML with boxes), TSV, searchable PDFs, or ALTO XML.
- LSTM-based (v4+) for solid accuracy (>95% on clean printed text/fonts); no GPU needed for basics.
- Mature ecosystem: Python wrappers (pytesseract), easy integration.
- Best for: Bulk clean archive digitization, simple printed forms, or as baseline in hybrids (VLMs correct its output).
- Limitations: Weak on complex layouts (no native tables/charts), handwriting (poor cursive), noise/rotation/multi-column—requires preprocessing/layout tools.
- Updates: Better binarization (Adaptive Otsu/Sauvola), image URL support.
Still relevant as a fast, zero-cost foundation.


Key Points on DeepSeek-OCR (3B Multimodal Model)
Efficient open VLM focused on document understanding, visual compression, and structured extraction (v2 updates).
- Handles tables, charts, geometric figures, multilingual/handwritten text, math, memes.
- Innovative DeepEncoder for complex layouts/multi-column/reading order.
- Token-efficient compression (7–20x reduction) for long-context processing.
- Strong practical accuracy without heavy resources.

Key Points on PaddleOCR-VL (0.9B Ultra-Compact VLM)
Lightweight, multilingual-focused for robust in-the-wild parsing (v1.5 updates).
- Supports 109+ languages with improved rare/ancient characters, multilingual tables, underlines, checkboxes.
- Strong on irregular layouts, low-quality scans, document-to-HTML conversion.
- Excellent for resource-constrained deployments needing broad linguistic coverage.
Key Points on OlmOCR-2 (7B/8B Model)
AllenAI fine-tune on diverse PDFs for English digitized print with unit-test rewards.
- Scores ~82.4 on olmOCR-Bench (+4 points over prior), strong on tables/multi-column/tiny text/formulas/handwritten additions.
- Trained on 270k+ pages (historical/legal/brochures/handwritten); outperforms tools like Marker/MinerU.
- Focuses on real-world OCR failures with high pass rates.
Key Points on Sarvam Vision (3B State-Space VLM)
India-focused (early 2026) for document intelligence in English + 22 official languages.
- State-of-the-art 84.3% on olmOCR-Bench (English subset), outperforming Gemini 3 Pro/DeepSeek variants.
- Best-in-class on Indic OCR (Hindi/Tamil/Telugu/Bengali/etc.), complex layouts, noisy/low-res scans, historical texts, textbooks, forms, multi-column/tables/charts.
- Fills regional gaps for government/education/banking KYC/archival use.

Key Points on Mistral OCR / Mistral OCR 3 (Proprietary Multimodal OCR API)
Mistral AI's flagship OCR service (launched 2025, with OCR 3 / mistral-ocr-2512 update in late 2025/early 2026), powers Document AI stack with state-of-the-art document understanding via API (cloud/self-hosted).
- Breakthrough accuracy: 74% win rate over OCR 2 on forms, scanned docs, complex tables, handwriting; internal benchmarks show 88.9% handwriting, 96.6% tables, 96.7% historical scans, often outperforming Azure/Textract/Gemini.
- Multilingual/multimodal: Native support for thousands of scripts/languages, extracts interleaved text + embedded images, preserves structure (tables, math equations, figures) in Markdown/HTML-enriched output.
- High speed & cost-efficiency: Up to 2,000 pages/min on single node, priced at $2/1,000 pages ($1 with batch discount); ideal for RAG on complex PDFs/slides.
- Enterprise features: Structured JSON extraction, forms parsing, low-quality scan handling; integrated in Mistral AI Studio playground and Azure AI Foundry.

Multilingual Support of OCR Models
Multilingual capabilities explode: PaddleOCR-VL (109+), DeepSeek-OCR (~100), Chandra/Qwen3-VL (30–40+ incl. low-resource/ancient scripts). Compact models like Granite-Docling-258M add flexibility.
OlmOCR-2 prioritizes English speed/precision, while Sarvam Vision dominates Indic gaps—superior on mixed scripts, low-res scans, cultural formats for regional apps.
Enter LandingAI's Agentic Document Extraction (ADE): Production-Ready Vision-First
Founded by AI legend Andrew Ng, LandingAI brings enterprise-grade polish with Agentic Document Extraction (ADE)—a platform that treats documents as visual artifacts, not flattened text. Powered by proprietary vision foundation models like Document Pre-trained Transformer-2 (DPT-2) and agentic workflows, ADE breaks PDFs/scans into components (borderless tables, checkboxes, signatures, diagrams, embedded images) and reasons iteratively over layout, reading order, and semantics.
Key standouts:
- Visual Grounding — Every field ties back to exact page coordinates (bounding boxes) for verification and near-zero hallucinations.
- Structured Outputs — Clean Markdown summaries, hierarchical JSON for key-values/tables—ideal for RAG, analytics, or automation.
- Real-World Robustness — Excels on skewed invoices, dense financials, medical claims, legal contracts, barcodes, formulas, and charts—far beyond text-only OCR + LLM hybrids.
- Benchmark Dominance — Achieves ~99.15–99.16% on DocVQA (validation set) without image access in QA—superhuman-level parsing where one strong parse enables lookup-style answers. Independent tests rank it top among agentic tools (e.g., 69/100 composite score).
- Speed & Enterprise Features — Up to 17x faster in benchmarks, hundreds/thousands of pages/minute, confidence scores, audit trails, governance, batch support, zero data retention, and Snowflake-native integration.
ADE's "vision-first" philosophy—detecting layout/semantic relationships, preserving spatial context, zero-shot parsing—makes it ideal for finance (KYC/statements), healthcare (claims/forms), legal, and insurance, where traceability and compliance are non-negotiable. Users report 90%+ reductions in info search time after processing billions of pages.
Here are some standalone visuals specifically focused on document extraction technologies:
Standalone Visuals: Document Extraction in Action
Examples of bounding boxes, structured outputs, layout detection, Indic/multilingual parsing, and real invoice/form extraction.

Benchmark & Results
Conclusion: The Future of Document AI in 2026 – Hybrids Win, India Leads
The pure OCR era is far from dead—tools like Tesseract remain unbeatable for simple, high-volume, cost-free digitization of clean print. But 2026 belongs to intelligent multimodal systems that understand layout, context, handwriting, tables, and multilingual nuances.
- For global/open-source excellence: Chandra (top benchmarks, layout mastery) and DeepSeek-OCR (efficiency) lead.
- For Indic/regional strength: Sarvam Vision stands out with 84.3% on olmOCR-Bench, outperforming even Gemini 3 Pro on Tamil/Hindi/Telugu-heavy docs—perfect for government records, education textbooks, banking KYC, and archival projects.
- For enterprise/production speed & accuracy: Mistral OCR 3 delivers frontier performance (88.9% handwriting, 96.6% tables) at commodity pricing ($1–2 per 1,000 pages), making it ideal for scalable pipelines.
- For verifiable, auditable deployment: LandingAI ADE bridges raw extraction to trusted intelligence with grounding and governance.
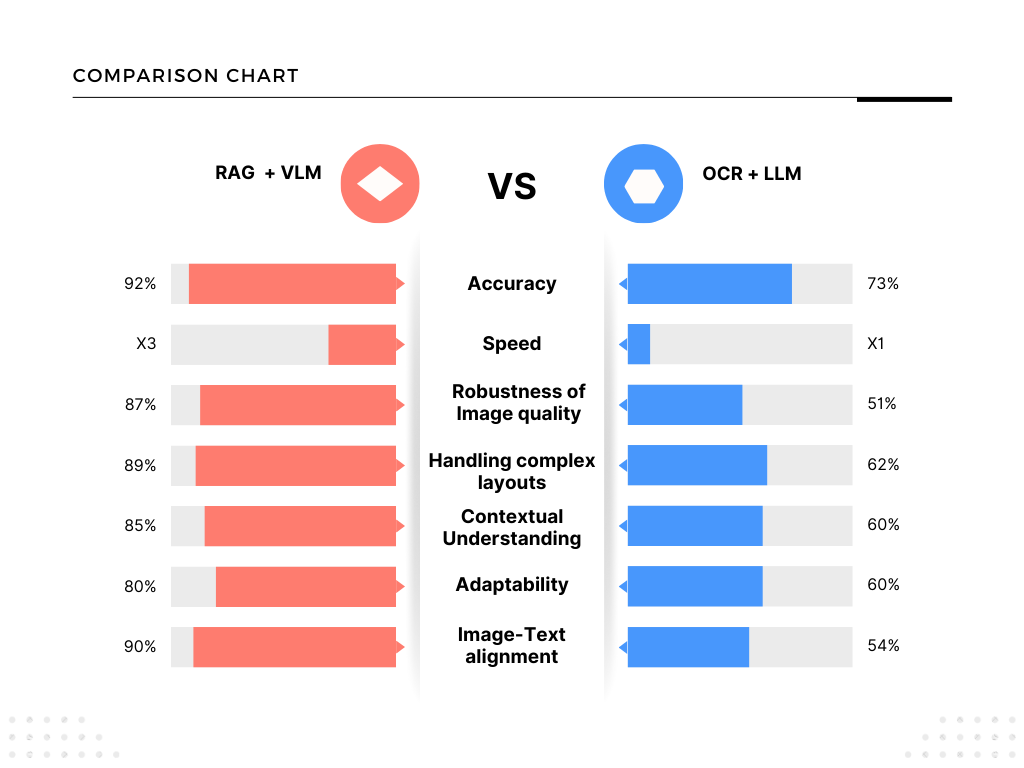
The winning strategy? Hybrids: Use Tesseract/PaddleOCR for bulk first-pass → feed noisy/complex pages to VLMs like Sarvam Vision or Chandra → refine with agentic tools like ADE or Mistral API. This approach cuts manual review by 80–90%, saves time, and unlocks RAG/agent automation.
In India especially, locally-tuned models like Sarvam Vision prove that sovereign, culturally-aware AI can outperform global giants on real tasks. The future isn't one "best" model—it's the right stack for your documents.