Making LLMs Use GraphQL APIs (Without Wasting Tokens)
.png&w=3840&q=75)
If you’re wiring LLMs to real backends, GraphQL is actually a very good fit.
Not because it’s trendy. But because LLMs benefit from being able to request exactly the fields they need — nothing more.
This post covers:
- Why GraphQL works well for LLM workflows
- Why most GraphQL MCP implementations are inefficient
- A better 3-operation approach (inspired by Grafbase)
- How we use this at Eminent AI Labs
Why GraphQL Fits LLM Workflows

The biggest cost in LLM systems isn’t compute — it’s tokens.
If your backend returns large JSON payloads and your model only needs 3 fields out of 40, you're wasting:
- Tokens
- Latency
- Money
- Context window
GraphQL solves this cleanly:
query {
user(id: "123") {
name
email
}
}The model requests exactly what it needs. No overfetching. No extra tokens.
For LLM workflows where context is precious, this is extremely useful.
The Problem With Most GraphQL MCP Servers
Most GraphQL MCP implementations today are naive.
They typically expose:
- getSchema
- execute
That sounds fine, but here’s the issue.
getSchema returns the entire GraphQL schema, which is often huge.
execute runs a query.
To generate a correct query, the model usually needs to:
- Call getSchema
- Parse the entire schema
- Decide what types and fields to use
- Then call execute
For large schemas, this can easily consume thousands of tokens before the model even makes a useful request.
This defeats one of the main advantages of GraphQL in LLM systems.
A Better Approach: 3 Focused Operations
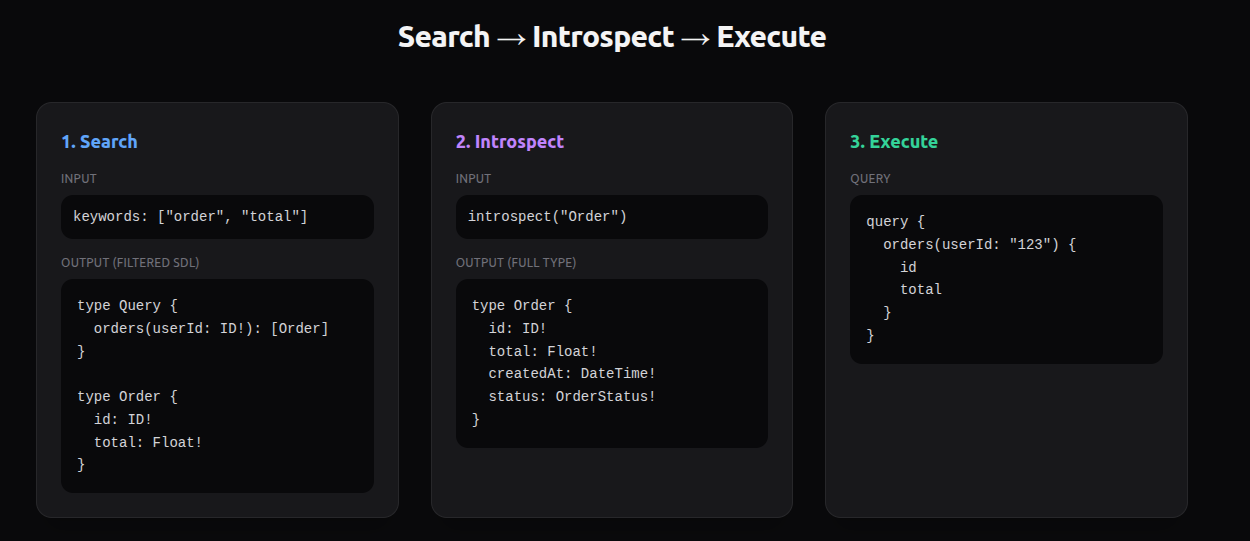
A better approach, originally introduced by Grafbase for their MCP server, is to expose three operations:
- search
- introspect
- execute
Instead of giving the model the entire schema, we let it progressively discover what it needs.
Search
search returns the most relevant subset of the schema as SDL.
It’s backed by a text-based index built at server startup. The index is aware of:
- Types
- Fields
- Arguments
- Input types
- Return types
Important detail:
- For input types and arguments → return full definitions
- For return types → limit by max depth
This gives the model enough structure to reason about the API without flooding it with everything.
Introspect
If the model needs more detail about a specific type, it calls:
introspect(typeName)
Now it gets precise information only for that type.
Exploration becomes incremental and cheap.
Execute
Once the model understands what it needs, it calls:
execute(query)
No schema dump required.
Why This Is Better
With this approach:
- We never pass the entire schema
- We drastically reduce token usage
- We reduce reasoning noise
- We improve reliability
Instead of overwhelming the model, we guide it.
The model behaves more like a developer:
- Search for relevant parts
- Inspect specific types
- Execute a query
Doc strings
This approach works best when we have proper documentation for queries, mutation, types. Documentation can be added using simple doc strings
How We Use This at Eminent AI Labs
At Eminent AI Labs, we’re using this approach for a complex GraphQL API.
Our schema is large. Sending the entire SDL to the model was expensive, slow, and hard for the model to reason about.
The indexed search → introspect → execute flow made a big difference:
- Lower token usage
- More accurate queries
- Better tool selection
- Faster workflows
It scales much better as the schema grows.
Credit Where It’s Due
This 3-operation pattern was introduced by Grafbase for their rust based MCP server in the Grafbase Gateway. We adopted their approach for our usecase.
Final Thought
If you're building LLM systems over real production GraphQL APIs, don’t dump the entire schema into the model.
Give it:
- A way to search
- A way to inspect
- A way to execute
Design your API surface for LLM reasoning, not just human developers.
You’ll save tokens, latency, and a lot of frustration.
Written with the help of ChatGPT.